At the beginning of 2023 Google released an open-source Software Composition Analysis tool — osv-scanner. In this article I’m presenting how it can be configured and utilised using popular open-source projects as examples.
Software Composition Analysis
Software Composition Analysis (SCA) is a process that can aid developers and security engineers to effectively identify project’s dependencies and their open-source vulnerabilities during the Software Development Lifecycle. On the market there is a number of solutions that can be easily integrated with existing projects. Few examples of SCA solutions that can be used with more than one technology:
- Dependency-Check supported by OWASP
- Google osv-scanner
- Semgrep Supply Chain
- Snyk Open Source
Google osv-scanner
Google osv-scanner is a Go based open-source SCA tool that can be used with a number of technologies such as Python, Java, JavaScript, Go and more. Additionally, it allows to perform a container scanning against Debian based images. It is using an open-source osv.dev database for quering details about open-source vulnerabilities. The tool works effectively with lockfiles, dependency manifests and Software Bill of Materials (SBOMs).
Configuring osv-scanner with Keras — Deep Learning For Humans Project
Let’s jump to a case study where I present how this SCA solution can be used in a real life scenario. We will perform the scanning locally to understand its capabilities and have a background for enabling this SCA solution in CI/CD.
I decided to use some popular project that is using requirements.txt to store project’s dependencies as a case study and Keras was chosen as a testing project.
Keras is a deep learning API written in Python, running on top of the machine learning platform TensorFlow. It was developed with a focus on enabling fast experimentation and providing a delightful developer experience.
Firstly, the SCA tool can be downloaded with the following command in Linux:
wget https://github.com/google/osv-scanner/releases/download/v1.3.6/osv-scanner_1.3.6_linux_amd64<br>chmod +x osv-scanner_1.3.6_linux_amd64More installation materials are included in the official documentation and released binaries. Also, osv-scanner can be found in popular package managers.
Next, the scanning can be executed against a target directory or a specific lockfile. In our case we will use a keras directory containing our testing project which I already cloned:
./osv-scanner_1.3.6_linux_amd64 keras/The scanning output can be observed below:
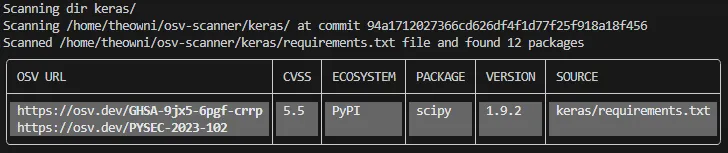
The output is presented in a table format by default. This table presents such pieces of information as OSV URL to vulnerability details, CVSS score, ecosystem (package manager), affected package, its version and the source file where the dependency was identified. Furthermore, the tool also returns non-zero exit code when it detects vulnerabilities.
This output is enough to assess the risk manually by following OSV URL. In this case, we can observe that Keras project returns two OSV URL:
Actually, following URLs lets us understand that this is actually one vulnerability “Potential memory leak” having CVE-2023–25399 number and CVSS score set to 5.5 which is considered as a medium severity issue.
Experienced engineers with security knowledge may decide that such vulnerability may be a low severity risk issue in their opinion and would need more data to assess the risk properly. How they could get more info from this tool? It’s rather easy with --format json flag. Let’s see the output now:./osv-scanner_1.3.6_linux_amd64 –format json keras/
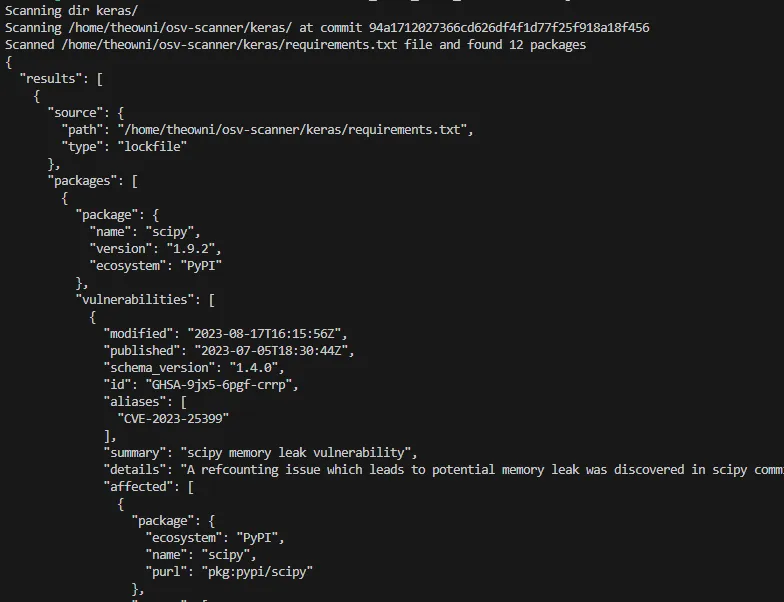
The JSON format presents much more data than table such as:
- Vulnerability published date — 2023–07–05T18:30:44Z;
- Summary — scipy memory leak vulnerability;
- Details — A refcounting issue which leads to potential memory leak was discovered in scipy commit 8627df31ab in `Py_FindObjects()` function.;
- Affected version ranges — <1.9.3;
- Fixed version — 1.10.0;
- CVSS vector — CVSS:3.1/AV:L/AC:L/PR:L/UI:N/S:U/C:N/I:N/A:H;
- CWE — CWE-400;
- Severity — MODERATE;
Such data with some context information could be effectively used to assess the actual risk of this vulnerability.
More interesting flags are:
--recursive— checks subdirectories for supported lockfiles--experimental-call-analysis— enables experimental call analysis that detects if the affected code is reachable--docker— scans Docker image with specified name
It should be also noted that it’s possible to ignore specific vulnerabilities based on their IDs by using --config config.toml flag. Assuming that the detected vulnerability should be ignored by scanning mechanism, the following config.toml file can be created:
[[IgnoredVulns]]
id = "GHSA-9jx5-6pgf-crrp"
# ignoreUntil = 2022-11-09 # Optional exception expiry date
reason = "Risk accepted for this type of issues as project is used only locally by one developer"
[[IgnoredVulns]]
id = "PYSEC-2023-102"
# ignoreUntil = 2022-11-09 # Optional exception expiry date
reason = "Risk accepted for this type of issues as project is used only locally by one developer"What About Transitive Dependencies?
As you may know a majority of vulnerabilities are related with transitive dependencies which may not be included in a project dependencies directly but are pulled with them when dependency tree is resolved. Research performed by Snyk mentions that over 78%, and Endor Labs mentions that about 95% of vulnerabilities, are coming from indirect dependencies. Based on these numbers it becomes obvious that transitive dependencies needs to be also identified to assess the security risk properly.
By default osv-scanner doesn’t resolve dependency tree of a project if it’s not already included in the scanned file. This problem may occur for dependencies declared in requirements.txt file (for Python) or in pom.xml (for Java). On the other hand, this problem doesn’t exist if your project already is using SBOM or a package manager that resolves dependencies and stores them as some kind of a lockfile. For example with Poetry, this problem is solved with a poetry.lock lockfile containing all of the direct and transitive dependencies installed within your project.
As you can see transitive dependencies might be problematic for some cases and this is a downside of this tool in the context of using it out of the box directly in CI/CD pipeline.
Scanning Transitive Dependencies
Scanning Python Project
As I mentioned such dependencies can be resolved during CI/CD and stored in the SBOM file. Next, such file can be easily scanned with osv-scanner!
As SBOM is a topic for a different more comprehensive article let’s assume that in your environment you have already installed Keras dependencies. If you don’t have them installed already, you can install them with the following commands in a virtual environment:
# create virtualenv for resolving dependencies
virtualenv -v .venv/ -p python3
source .venv/bin/activate
# install dependencies
pip3 install -r keras/requirements.txt
# dump installed dependencies to reqs_to_scan.txt
pip3 freeze > requirements.txt
# leave virtualenv
deactivate
# perform SCA scan for direct and transitive dependencies
./osv-scanner_1.3.6_linux_amd64 --lockfile requirements.txtNow, osv-scanner presents the same findings but actually 63 packages were scanned (earlier 12 packages):

By installing dependencies manually we were able to “resolve a dependency tree” and obtain a full list of packages to scan. In a similar way a dedicated Python pip-audit vulnerability scanning tool works as it resolves dependencies by installing them in a dedicated environment.
Scanning Java Project
I wouldn’t be myself if I didn’t present how osv-scanner is working with Java! I’ve chosen an Apache Spark project which is using pom.xml file to specify dependencies.
Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis
The SCA scanning can be inititated in a similar way as previously using:
./osv-scanner_1.3.6_linux_amd64 sparkThe output is presented below:
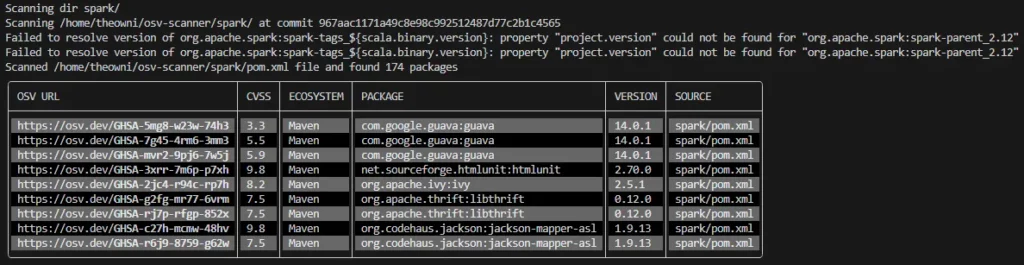
It should be noted that pom.xml may contain only direct dependencies. Currently, there is no generic way to scan both direct and transitive dependencies easily with osv-scanner. There are GitHub issues raised with questions about transitive dependencies like this one in context of Java:
Based on the discussion, looks like SBOM is currently the best option to have ability to scan both direct and transitive dependencies. I believe it’s time to review tools and approaches for generating SBOM files 🤔.
Summary
As you can see osv-scanner can be a great fit to identify security vulnerabilities in direct open-source dependencies. However in some cases it needs an additional effort in configuring projects to obtain a full picture of all of the direct and transitive dependencies installed with your project.
Pros
- It’s free and an open-source solution;
- It uses a reliable source of open-source vulnerabilities;
- It can be configured for a number of technologies;
Cons
- At large scale it may require a significant amount of effort to adjust projects to fully utilize its power. Introducing SBOMs looks like the most effective solution to this problem.
- No risk or prioritization details provided. It should be noted that CVSS is not great for assessing them properly. As a result non experienced security engineers may end up with a number of high/critical vulnerabilities which don’t pose a major security risk in their environments.
Still, taking into account advantages if you don’t have any SCA solution in place yet I can recommend this one! Furthermore, it looks like the tool is still evolving and more features might be implemented over a time such as ability to scan transitive dependencies.